


【ICO60億円】“偽データ”と、分散型プラットフォームでAI市場を覆す、エストニアの超新星【日本メディア初取材】

「リアルなデータをAIに覚えさせる代わりに、CG技術でリアルそっくりの世界を作って、それをAIに学習させます。」
「少数の巨大企業が寡占する今のAI市場はフェアじゃない。僕たちは、20年先のAI市場を見据えて、この分散型AIプラットフォームを作っています。」
2018年4月東京ビックサイトで開催された第3回 AI・人工知能 EXPO。
そこで、多くの日本企業の注目を集めた、エストニアのスタートアップがあった。
彼らの名は、Neuromation(ニューロメーション)。
ブロックチェーンを使った分散型AIプラットフォームと、全く新しいデータのラベリング作業を武器に、AIの「真の民主化」を目指す。

昨今、多くの大手IT企業が、「AIの民主化」を唱え、AI開発を多くの人が、より簡単にできるようにしようと努めている。しかし、Neuromationが唱える「AIの民主化」は大企業のそれとは全く異なっている。
「多くのAIプラットフォームは、企業がユーザーに対して一方的にリソースを提供しています。私たちは、AIに必要なリソースをユーザーが自由に売り買いできるようにして、その価格をユーザー自身が決められる分散型プラットフォームを構築しています」
Neuromationの新しさは、分散型プラットフォームだけではない。機械学習に必要な教師データを、なんと”偽物”の合成データで作っているのだ。
「私たちの合成データを使えば、データのラベリングにかかっていたコストと時間を何十倍、何百倍と減らせます。リソースのないエンジニアも大企業の力を借りず簡単にAI開発ができるようにするんです」
合成データ、分散型プラットフォーム……現在のAI開発の常識を大きく覆す、何もかもが新しいエストニア企業に迫る!
【ICOで60億円】IT先進国エストニアから来た刺客。
―――ICOで8時間で60億円の資金調達をしたと聞きました。しかも、そのうち23%(およそ14億円)は日本ユーザーからだったらしいですね。
Mccullum氏「 ICOはかなり成功したと思います。日本からの関心も高いようで嬉しいです。これは間違っているかも知れませんが、日本のAI事情は、アメリカとはかなり違っているように感じます。」
―――というと?
Mccullum氏「日本では、大企業の一部門がAI事業をやっていることが多いと感じました。アメリカでは、小さいグループ・スタートアップがAIをやっていることが多いです。そして、みんな結局Googleに買収されていくという…笑。」
―――そうなんですね。日本にもAIベンチャー・スタートアップはあると思いますが、確かにGoogle等に買収されたという話はあまり聞かないかも知れません。
Mccullum氏「大企業の方がやはりAI開発に必要なリソースを沢山持っていますから、買収に応じるのでしょうね。
でも、私たちNeuromationは、小さい会社のAIエンジニア、リソースを十分に持っていないけどアイディアは素晴らしいものがある、というAIエンジニアたちにこそ、手軽かつ簡単にリソースを与えたいと思っています。」
―――それを、分散型プラットフォームでやるんですよね?
Mccullum氏「はい。でも、それだけじゃないんです。
AIに必要なリソースは、基本的に3つあります。AIを学習させるための膨大な量のデータ、機械学習モデル、そして計算処理するためのコンピューティングパワー。 私たちは、この3つすべての要素に対して、革新的な解決策を提供します。」

AIの教師データ生成は、ブラックな作業かつ超高コスト。
Mccullum氏「AIに必要なリソースの1つ目、それは膨大な量のデータです。データ自体を集めるのは比較的簡単ですが、大変なのはここからで、集めたデータを機械学習に利用可能にするには、それぞれに意味づけ―ラベリングをする必要があります。」
Katz氏「 今、どうやってラベリングしていると思いますか?人力なんですよ!高質な機械学習のためには、高質なラベリングが必要になるからです。」
Mccullum氏「 機械学習のためのデータのラベリングを代行するサービスをやっている会社も今はあります。でも、そういう会社に『実際、どうやってラベリングをしているんですか?』って聞いてみたら良いかもしれないですね。答えたがらないかも知れないけど…。
大抵は、ベトナムなど人件費の安い国に工場を構えて、その中で何十人という人たちに、ラベリング作業を人力でやってもらっていることが多いんです。」
Katz氏「しかも、1人につき1作業じゃなくて、ミスを防ぐために、2人1組で確認しながら作業していることもあります。とてつもない人件費と人力が「ラベリング」という単純な―しかし、高質な学習のためには欠かせない―作業に費やされているんです。
具体的には、こういうデータがあります。
データのラベリング作業に、1枚につき0.2ドル(約21円)支払われるとします。とても安い相場ですが、もし教師データのために10億枚ラベリングするとすると、それでも2億4000万ドル(約257億5,383万6,249円)という莫大なコストがかかります。」

―――Neuromationはそのラベリング問題に対して、どういう解決策を持っているんですか?
Mccullum氏「 私たちは、シンセティックデータ(合成データ)を作って、それをAIに学習させます。簡単に言うと 、リアルなデータをAIに覚えさせる代わりに、CGのような技術でリアルそっくりの世界を作って、それをAIに学習させるやり方です。」
アニメーターの技術で作った「仮想の世界」で、AIを学習させる?!
Mccullum氏「 これを見て下さい。

これは、実はすべて本物の商品の写真ではありません。リアルなボトル、缶を基にして作ったシンセティックデータです。そして、このデータを、AIに学習させるんです。」
Katz氏「一枚、一枚、データをラベリングする必要はもう無くなります。
どれが何と言うものなのかは、ラベリングせずとも、すでに情報が入っているからです。
しかも、リアルなデータよりも詳細な情報をAIに教えることができます。シンセティックデータであれば、1ピクセルごとの詳しい情報が得られます。」
―――でも、どうやってシンセティックデータを作っているんですか?とても難しそうに聞こえます。
Mccullum氏「実は、そんなに難しくないんです。例えば、ペットボトルのシンセティックデータを作るには、6アングルから写真を撮ります。そして、それらの写真を基に、CGモデルを生成していきます。
私たちがシンセティックデータを作るために使っている技術は、ゲームやアニメのクリエーターたちが使っているものと同じです。彼らが作ってきた技術には、本当に素晴らしいものがあります。」
―――CGのスペシャリストがチームにいるんですか?
Katz氏「超スペシャリストがいますよ!Neuromationのファウンダーは、実はもともとアニメーターです。
もともと彼は、子ども向けのコミックやアニメを作っていました。でも、ある日、『本物そっくりなアニメの世界にAIを入れれば、そこでAIを学習させることができるんじゃないか』と考えたそうです。賢い人ですよ、本当に。」
―――アニメーション技術を教師データ生成に使うって、ものすごく新しい考え方ですよね。
Mccullum氏「そう、新しいからこそ、disruptive(破壊的)なんです。Neuromationは、もちろんAIの知識もベースになっていますが、知識だけでなく想像力も同じくらい大きな地位を占めています。」

雨、光、言語……シンセティックデータなら自由自在に変えられる。
Mccullum氏「また、このシンセティックデータなら、新たに条件を付け加えることも簡単にできます。
例えば、ペットボトルの画像を学習させたいとします。一言で「ペットボトル」と言っても、いろいろな条件のペットボトルが想定できます。横に倒れているペットボトル、直立しているペットボトル、暗い光の中にあるペットボトル……等々。今広く使われているデータ収集の方法だと、そうした違う環境にあるペットボトルの画像をいちいち集めなくてはいけません。
シンセティックデータを作るためには、ペットボトルの形の「ルール」を理解する必要があります。しかし、一度そのルールがわかって、シンセティックデータを作ってしまえば、あとはどんなペットボトルにも適用することが出来るんです。」

Katz氏「見たこともないようなペットボトルの形じゃない限り、新たに写真を撮ってデータを取る必要はないんです。今わたしたちが持っているペットボトルのデータは、日本のものではありませんが、日本のペットボトルを学習させるのも簡単です。シンセティックデータ上で、ラベルの言語を変えればいいだけなので。」
―――それは、教師データを作る際に、かなりの時間・労力の節約になる気がします。実際、このスーパーマーケットのシンセティックデータを作るのはどのくらいの時間がかかったのでしょうか?
Katz氏「技術者を呼んできますね。
【5分後】
このスーパーマーケットの例だと、1棚あたりにかかった時間は、「一瞬」だそうです笑!
というのも、すでにペットボトルのシンセティックデータは持っていましたから、あとはそれを並べていけばいいだけだったようです。このように、一度使ったデータを利用すると、さらに速いスピードでデータを生成することが出来ます。普通のやり方と比べて、Neuromationのシンセティックデータを使えば、何十倍、何百倍のコストと時間を節約することができます。」

―――なるほど、やっとわかってきました。
でも、まだこれ解決策の1つ目ですよね?もうすでに盛りだくさんなのですが…。
Mccullum氏「私たちの目的は、AIに必要なリソースを小規模なAIエンジニアチームに与えることです。
今お話ししたシンセティックデータは、その一手段にすぎません。」
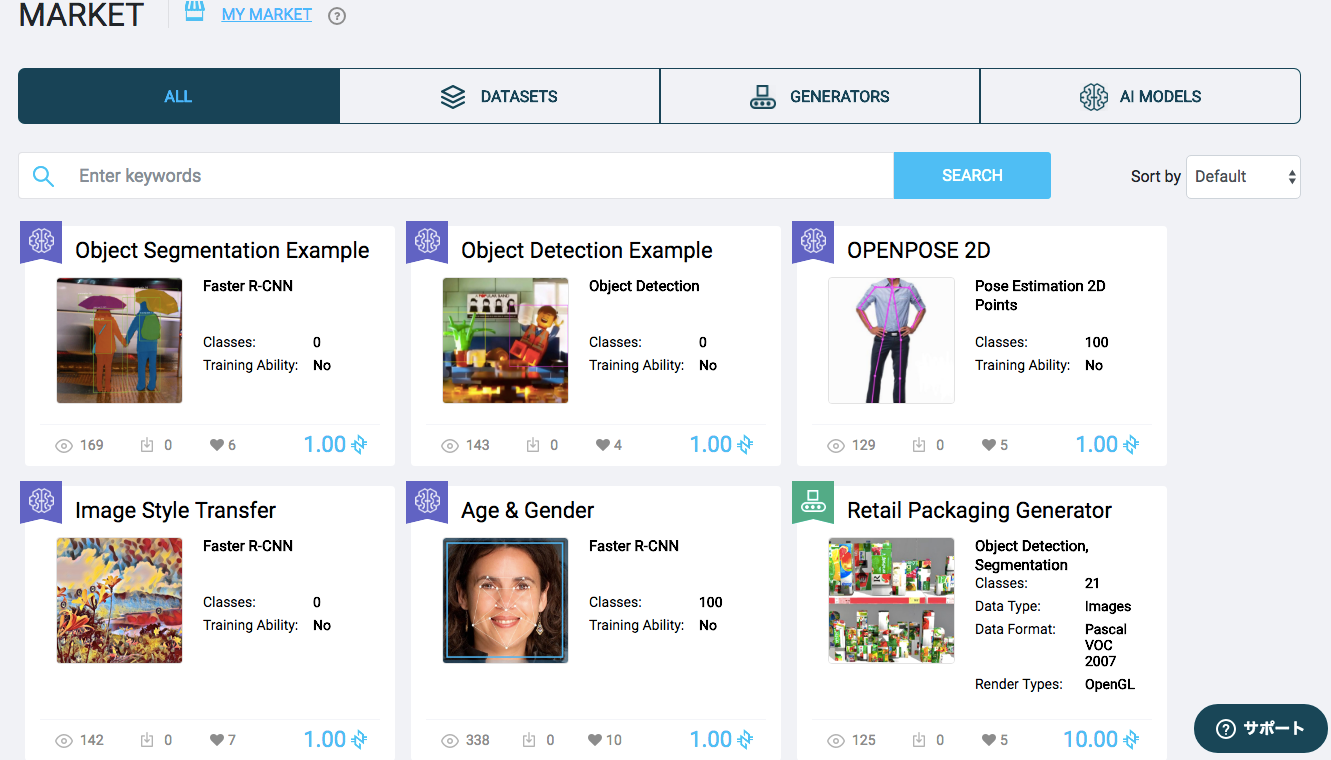
「今のAIは20年前のウェブサイトと同じ」分散型プラットフォームで近づく、AIの真の民主化
Mccullum氏「私たちの2つ目の手段は、ブロックチェーンを使った分散型AIプラットフォームです。
AI開発に必要なリソースすべて―データセット、機械学習モデル、そしてコンピューティングパワーをユーザーがNeuroToken(NTK)で自由に売り買いできることを目指しています。現在は、Neuromationが作ったシンセティックデータや機械学習モデルが売られていますが、私たちは、自分たちの作ったモデルやデータセットを売って商売することを目的とはしていません。
1番の目的は、AI開発の価格を市場に決めさせて、もっと手軽で低価格なものにすることです。」
Mccullum氏「ところで、20年前、ウェブサイトを作るのにいくらかかったか知っていますか?」
――――知らないです。私まだ3歳とかです。
Mccullum氏「ああ、年を取った感じするなあ笑。僕は、大学生でした。当時、ソニーなどの大企業は何千万とかけて、ウェブサイトを制作していました。そのくらい、ウェブサイト開発は難しいことで、限られた人にしかできないことだったんです。
でも、今ウェブサイト作るのにいくらかかりますか?今のAI開発は、20年前のウェブサイト開発と同じ状況です。AI価格のボトルネックは、リソースが広く行き渡っていないこと。だからこそ、リソースを持つ大企業が価格を一方的に決めてしまっている。そこを、僕たちは分散型のAIプラットフォームを通じて、突破していこうとしています。
そうすれば、価格はこれからもっともっと安くなるはずです。」
――――現在、データセットと機械学習モデルが購入可能だと言うことですが、コンピューティングパワーはいつ頃になるのでしょうか?
Mccullum氏「今年の末ですね。なぜかというと、コンピューティングパワーを売り買いできるようにするのが1番難しいんですよ。
ブロックチェーンのマイニングで使用されているコンピューティングパワーを活用しようと考えています。AI開発のコンピューティングパワーが今足りていないので、マイナーたちが計算能力を提供してくれれば、ブロックチェーンのマイニングの3~5倍利益が出る計算になっています。」
――――シンセティックデータから、分散型コンピューティングパワーまで、本当にすべて新しい考え方ですね…!
NY、ウクライナ、イスラエル、エストニア…世界中から集まった少数精鋭のチームメンバー。
―――皆さん、普段はエストニアにいらっしゃるのでしょうか?私は個人的に、エストニアが大好きなのですが…
Mccullum氏「残念だけど、僕はアメリカ人で(笑)、普段はニューヨークで仕事をしています。」
Katz氏「僕は南アフリカで生まれて、今はずっとイスラエルにいます。」
―――そうなんですか!皆さん世界中バラバラに散らばっているんですね。
Mccullum氏「そうですね、ファイナンシャル担当はニューヨーク、Evanを含むデータサイエンティストは、イスラエルのテルアビブ、エンジニアとデータサイエンティストはウクライナ。エストニアは主にオペレーションです。
僕たちにとって、メンバーがどこにいるかはあまり重要じゃないんです。その人自身の才能の方がずっと大切だと思ってやってきました。セールス、エンジニア、CG…それぞれのプロフェッショナルを集めていった結果、こんなに世界中バラバラに散らばったチームになりました笑。」
Katz氏「Neuromationのチームは本当に賢い人が多いと思います。」
Mccullum氏「そう。初めてオンラインで会議したときに、『僕はもしかしてこの中で1番バカなんじゃないか』って焦りました。」

Katz氏「僕たちは、セールスとファイナンシャルだけど、エンジニアやデータサイエンティストともちゃんと話が出来るように、勉強の日々です。でも、やっぱり学んでいて面白いなと思うし、革新的なことをやっているんだと実感しますよ。」

インタビュー時、聞いたこともないようなアイディアが噴出し、熱く語るMcClum氏、Katz氏につられて、取材したこちらまで興奮し通しだった。二人ともエンジニアではないが、彼らのNeuromationのテクノロジーに対する強い愛情と誇りがよく伝わってきた。
「シンセティックデータ」と「分散型AIプラットフォーム」、そしてメンバーの熱い思いを携えて、全く新しいAIスタートアップ・NeuromationがAI開発の常識を大きく覆すだろう。Neuromationがもたらす、真のAIの民主化に期待が集まる。



